Boyuan Jiang(姜博源)
Senior Researcher at Tencent Youtu Lab.

I am a senior researcher at Tencent Youtu Lab, where I work on computer vision and machine learning. Recently, I am working for developing high-fidelity virtual try-on model for Tencent Cloud.
I got my B.A. from the Harbin Institute of Technology(HIT) in 2017 and got my M.A. degree from the Zhejiang University(ZJU) in 2020. I have ever worked at NetEase, SenseTime and Hikvision as research intern and joined Tencent Youtu Lab in 2020.
news
| 11/2024 | We released FitDiT, a high-fidelity virtual try-on work based on SD3. |
|---|---|
| 10/2024 | We released FluxFit, a virtual try-on work based on FLUX.1-dev. |
| 02/2024 | One paper about fast identity-preserved personalization accepted by CVPR’24. |
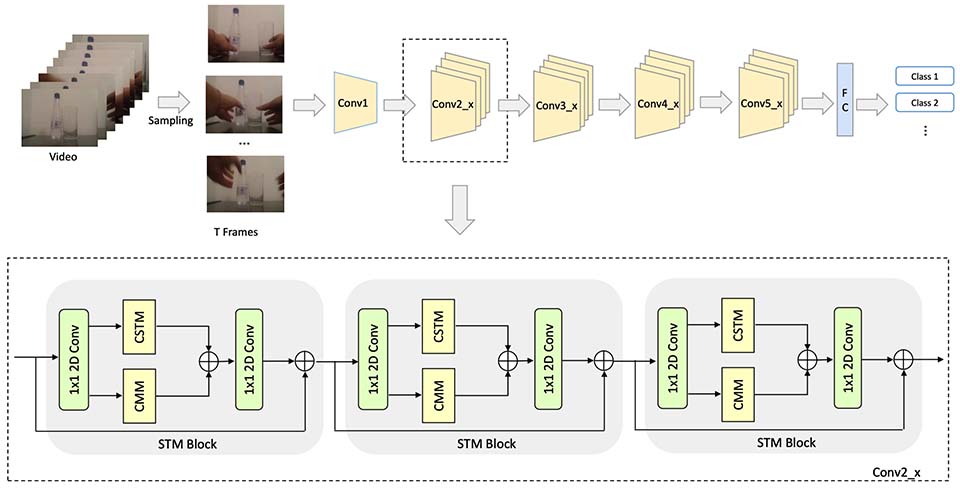
| 12/2023 | One paper about video action recognition accepted by AAAI’24. |
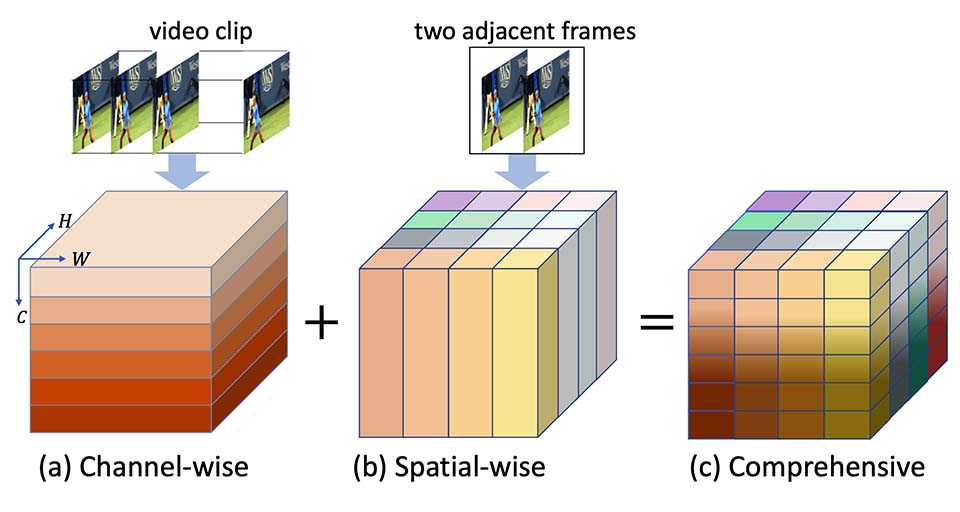
| 09/2023 | One paper about video frame interpolation accepted by IEEE Transactions on Image Processing. |
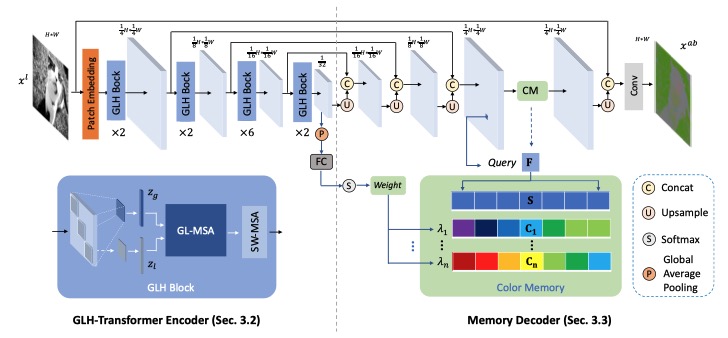
| 07/2022 | One paper about image colorization accepted by ECCV’22. |
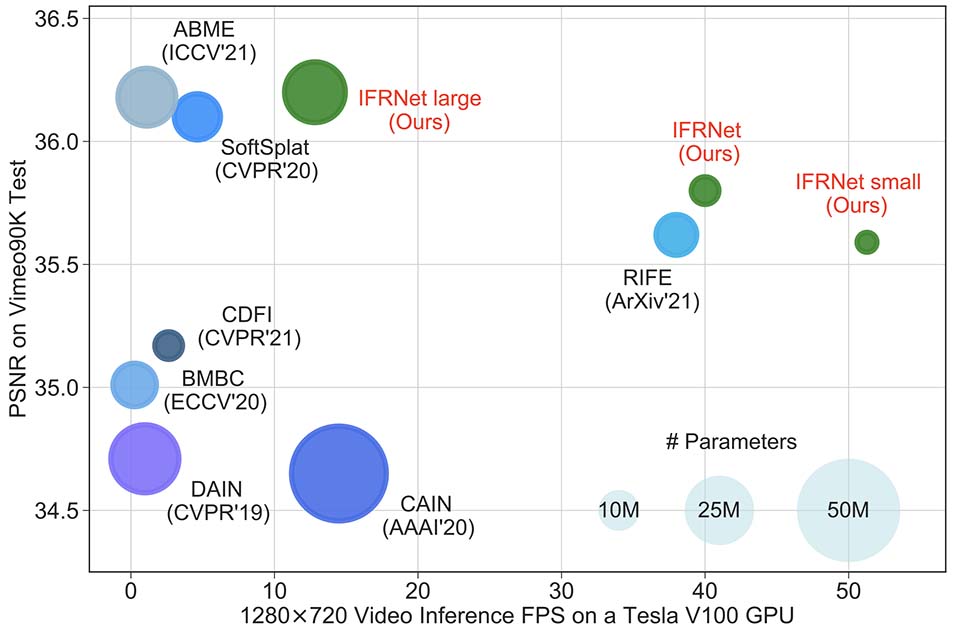
| 03/2022 | One paper about video frame interpolation accepted by CVPR’22. |
| 03/2021 | Our Team Imagination is the winner of CVPR NTIRE 2021 Challenge on Video Spatial-Temporal Super-Resolution. |
| 12/2020 | One paper about action recognition accepted by AAAI’21. |
| 04/2020 | I joined Tencent Youtu Lab. |
| 03/2020 | I graduated from Zhejiang University. |
| 02/2020 | One paper about domain adaption accepted by CVPR’20. |
| 07/2019 | One paper about action recognition accepted by ICCV’19. |
| 11/2018 | One paper about unsupervised domain adaption accepted by AAAI’19. |